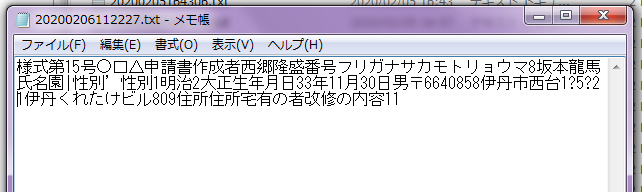
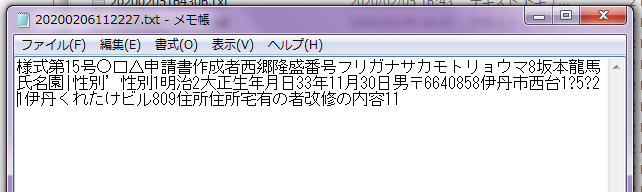
書類電子化とは書類をスキャンしてpdf形式等のデータにすることです。

↓

【 目次 】
- 1.書類電子化すると
①保管場所が不要となります。
机の上に山積みになっている書類が無くなります。
又、廃棄できずほとんど見たこともない書類が書棚から無くなります。
②必要書類を見つけるのが楽になります。
人の記憶は時間と共に薄れて行きますので、○○について記載された書類を
見つけるとなると、記憶と感で確かこのあたりかな、一度で見つけられれば
良いのですが、ヘタすれば全てを見ることになり大変です。
③ブッキングの手間がなくなります。
なぜブッキングしなくてよいかは後述します。
④書類の移動が不要です。
私が経験したことですが、会社の引越し時一番やっかいなのが書類の移動でした。
とにかく重く、廃棄した方が良いのか迷うくらいです、その時は廃棄するかの判断を
する時間が無いので、とにかく移動しましたが大変でした。
⑤地震、水没などの自然災害リスクの備えになります。
水に濡れた書類はインクが滲んだり、紙がくっついたりして大変な事になります。
火災で焼失した書類が会社にとって大切な物であれば相当の痛手になります。
- 2.書類電子化には2種類の方法があります
①画像として保存する方法
書類をイメージとして保存します。そのデータを開いて文字列をクリックしてもすべてが選択されます。文字は認識されません。
②文字列を含んだ文章として保存する方法
見た目は書類のイメージ通りですが中は文字列として保存されています。
そのデータを開いて文字列をクリックすると選択できます。
但し、画数の多い漢字、手書き文字、線と重なった文字はうまく認識されません。
文字化しますので処理に時間を要します。
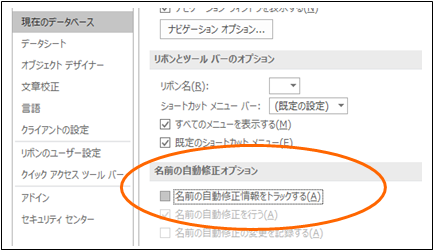
- 3.電子化されたデータのタイトル
①スキャナが読み取った用紙の内容から自動で生成
②読み取った日付で生成
③任意のタイトルを指定
3パターンがあります。「任意のタイトルを指定」は操作員の工数が生じます。
- 4.書類電子化する単位は
例えば厚さ5cmのバインダ分を1つのデータにするのか、内容によって細分するか単位を決める必要があります。
1つのデータにするとページ送りが大変です、内容によってデータ分けする方がタイトル分けされ見やすくなります。
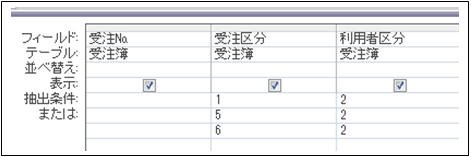
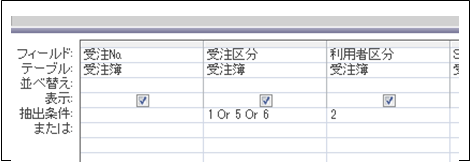
- 5.電子化されたデータの検索
正確にそして早く検索できるかが重要です。
①画像として保存されたデータ
検索方法は保存されたフォルダ、タイトル、作成日時だけです。
フォルダ分け、タイトルが重要になります。
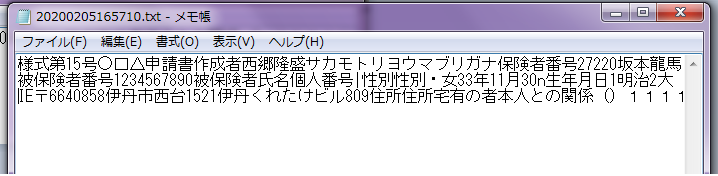
②文字列を含んだ文章として保存されたデータ
中に文字列が埋め込まれていますので文字列検索できるソフトを使えば該当する書類を抽出できます。
縦書き文章の文字列を検索するソフトは難しいのかあまり見ません。
しかし文字列検索は検索補助ですのでフォルダ分け、タイトルは重要です。
1.の③ブッキングの手間がなくなりますの説明
例えば氏名でブッキングする書類ならブッキングする事無く、氏名で検索キーにして
該当書類を抽出できるからです。
- 6.検索結果のサムネイル表示
書類電子化以外でも有効なのですが、検索結果データの1枚目のイメージを表示してもらえれば可視的に分かりやすくなります。
エクスプローラで「表示」を「アイコン」にすると1枚目がイメージとして表示されますが拡張子がjpg、png等に限られpdf、エクセル、ワードは、そのソフトのアイコンが表示されるだけです。
この機能をサムネイル表示といいます。
pdf、エクセル、ワードをサムネイル表示させるには別に仕組みを施す必要があります。