■OCR化で生成される文字列
書類電子化は「画像化」、「OCR化」の2つの方法がありますが、
OCR化について解析後の文字列をもとに詳しくご説明します。
- 目次
1.OCR化とは
2.変換された文字列(ほぼ成功例)
3.誤解析された文字列
4.まとめ
- 1.OCR化とは
光学文字認識のこと。
画像データ上にある文字と思われる部分を解析し、コンピューター上で扱える文字(テキスト)データに変換すること。
文字列は画像(PDF)に保存されています。
- 2.変換された文字列(ほぼ成功例)

OCR化した文字列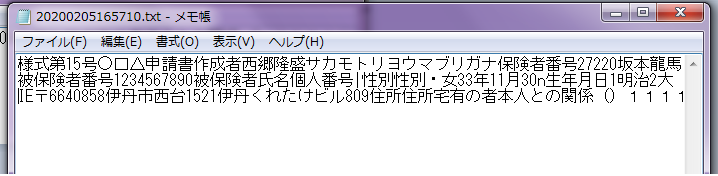
PDF内に保存されている文字列をメモ帳で開いた状態です。
説明のため改行していますが本当は右側に続いてします。
ほぼ正しく解析されています。
但し
①「サカモトリヨウマブリガナ」は「フリガナサカモトリヨウマ」では、
又、「性別性別・女33年11月30」あたりから微妙な文字列となっています。
②メモ帳の最後1111となっていますが実際は有りません。
③人間の感覚では上から順ではないのかと思いますが異なります。
- 3.誤解析された文字列

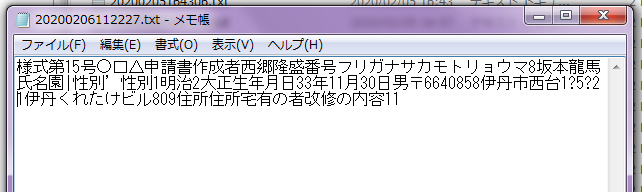
線に囲まれた番号12345678は全く認識されていません。
氏名は認識されていますが罫線、下線との関係で文字化けする時があります。
- 4.まとめ
帳票によって認識率が左右されます。
ご認識する要素として 以下が考えられます
①「シワ」、「折れ」、「変色」等の帳票劣化。
②文字の書体、大きさ、太さ
③文字のかすれ
④原稿が斜めになっている
⑤文字間隔が詰まっている
⑥FAXで送付された用紙
⑦罫線で囲まれている
⑧下線、横線にひっいている
⑨縦書きと横書きの混在
使い物にならないか?
いいえ、検索用途によると思います。
OCR文字列を全文検索すれば時間は要しますが条件文字に相当するPDFは抽出されます。
条件文字の追加の機能(AND)があれば 、 ある程度絞り込めます。
検索結果を1枚1枚開いて確認する時間と忍耐があれば使えます。